Vektorisierung#
In der numerischen Mathematik spielt die Effizienz von Algorithmen eine zentrale Rolle. Eine der wichtigsten Techniken zur Beschleunigung von Berechnungen in Python ist die Vektorisierung, die durch die Verwendung von NumPy Arrays anstelle von expliziten Schleifen erreicht wird. Vektorisierte Operationen sind in der Regel um ein Vielfaches schneller als Schleifen in Python, da NumPy diese Operationen in optimierten Routinen ausführen.
Rechenzeit messen#
Damit wir im Folgenden die Rechendauer verschiedener Code-Abschnitte vergleichen können, müssen wir die Rechenzeit messen können. Dafür benötigen wir das interne Paket \(\texttt{time}\) und die darin enthaltene Funktion \(\texttt{time()}\).
Mit dem Befehl \(\texttt{t = time.time()}\) wird die aktuelle Zeit abgerufen und in der Variable \(\texttt{t}\) gespeichert. Somit kann man die Rechenzeit messen, indem man die Zeit zu Beginn und zum Ende der Rechung abfragt und anschließend die Differenz betrachtet. Das Ergebnis ist die Rechenzeit in Sekunden.
import time
# Zeit VOR der Rechnung messen
startzeit = time.time()
# Code dessen Rechenzeit Sie messen wollen
# Zeit NACH der Rechnung messen
endzeit = time.time()
rechenzeit = endzeit - startzeit
In der folgenden Aufgabe haben wir Ihnen bereits ein Code-Beispiel vorgegeben. In dem Beispiel wird die Quadratwurzel eines Vektors eintragsweise berechent. Einmal über eine Scheife und einmal über die vektorisierte Operation \(\texttt{np.sqrt()}\).
Aufgabe 1.1
Variieren Sie die Länge \(n\) des Vektor. Wie verändert sich der Unterschied der Rechenzeiten beider Varianten?
import numpy as np
import time
n = 50
x = np.arange(1,n+1)
# Variante mit Schleife
sqrt_schleife = np.zeros(n)
startzeit = time.time()
for i in range(n):
sqrt_schleife[i] = np.sqrt(x[i])
endzeit = time.time()
print(f"Schleifenzeit: {endzeit - startzeit:.5f} Sekunden")
# Vektorisierte Variante
startzeit = time.time()
sqrt_vektorisierung = np.sqrt(x)
endzeit = time.time()
print(f"Vektorisierte Zeit: {endzeit - startzeit:.5f} Sekunden")
Aufgabe 1.2
Der folgende Code soll die \(\Vert \cdot \Vert_2\)-Norm aller Zeilen einer \(m \times n\) Matrix berechnen. Schreiben Sie die Berechnung einmal als Schleife über die Zeilen und einmal als vekorisierte Operation mithilfe des Befehls \(\texttt{np.linalg.norm}\). Machen Sie sich ggf. mit dem Befehl vertraut.
m = 1000
n = 100
A = np.random.rand(m, n)
# Variante mit Schleife
startzeit = time.time()
# Ihr Code
endzeit = time.time()
print(f"Schleifenzeit: {endzeit - startzeit:.5f} Sekunden")
# Vektorisierte Variante
startzeit = time.time()
# Ihr Code
endzeit = time.time()
print(f"Vektorisierte Zeit: {endzeit - startzeit:.5f} Sekunden")
Hinweis
Nutzen Sie für die Schleifen-Variante eine for-Schleife über \(\texttt{range(m)}\). Für die Vektorisierung verwenden Sie den Befehl \(\texttt{np.linalg.norm(A, axis = 1)}\).
Lösung
m = 1000
n = 100
A = np.random.rand(m, n)
# Variante mit Schleife
startzeit = time.time()
norm_schleife = np.zeros(m)
for i in range(m):
norm_schleife[i] = np.sqrt(np.sum(A[i, :] ** 2))
endzeit = time.time()
print(f"Schleifenzeit: {endzeit - startzeit:.5f} Sekunden")
# Vektorisierte Variante
startzeit = time.time()
norm_vektorisierung = np.linalg.norm(A, axis=1)
endzeit = time.time()
print(f"Vektorisierte Zeit: {endzeit - startzeit:.5f} Sekunden")
Vektorisierte Operationen#
Im Rahmen des Rechnen mit Arrays haben Sie bereits implizit weitere vektorisierte Operationen kennengelernt. Unter anderem die Addition eines Arrays \(\texttt{x}\) mit einem Skalar. So addiert zum Beispiel der Ausdruck \(\texttt{x + 5}\) den Wert \(5\) automatisch zu jedem Eintrag von \(\texttt{x}\), ohne dass Sie einen zusätzlichen Vektor mit dem Wert \(5\) erstellen oder durch die Einträge von \(\texttt{x}\) iterieren müssen. Diese vektorisierte Variante der Addition lässt sich auch auf Matrizen und Vektoren erweitern. Angenommen wir haben den Vektor
Dann können wir mit der korrekten Addition dieser beiden Vektoren die folgende Matrix erzeugen:
Auch hier hilft uns Vektorisierung Zeit zu sparen, denn es ist möglich einen Vektor spaltenweise und zeilenweise auf eine Matrix und einen anderen Vektor zu addieren. In unserem Beispiel kann das wie folgt aussehen.
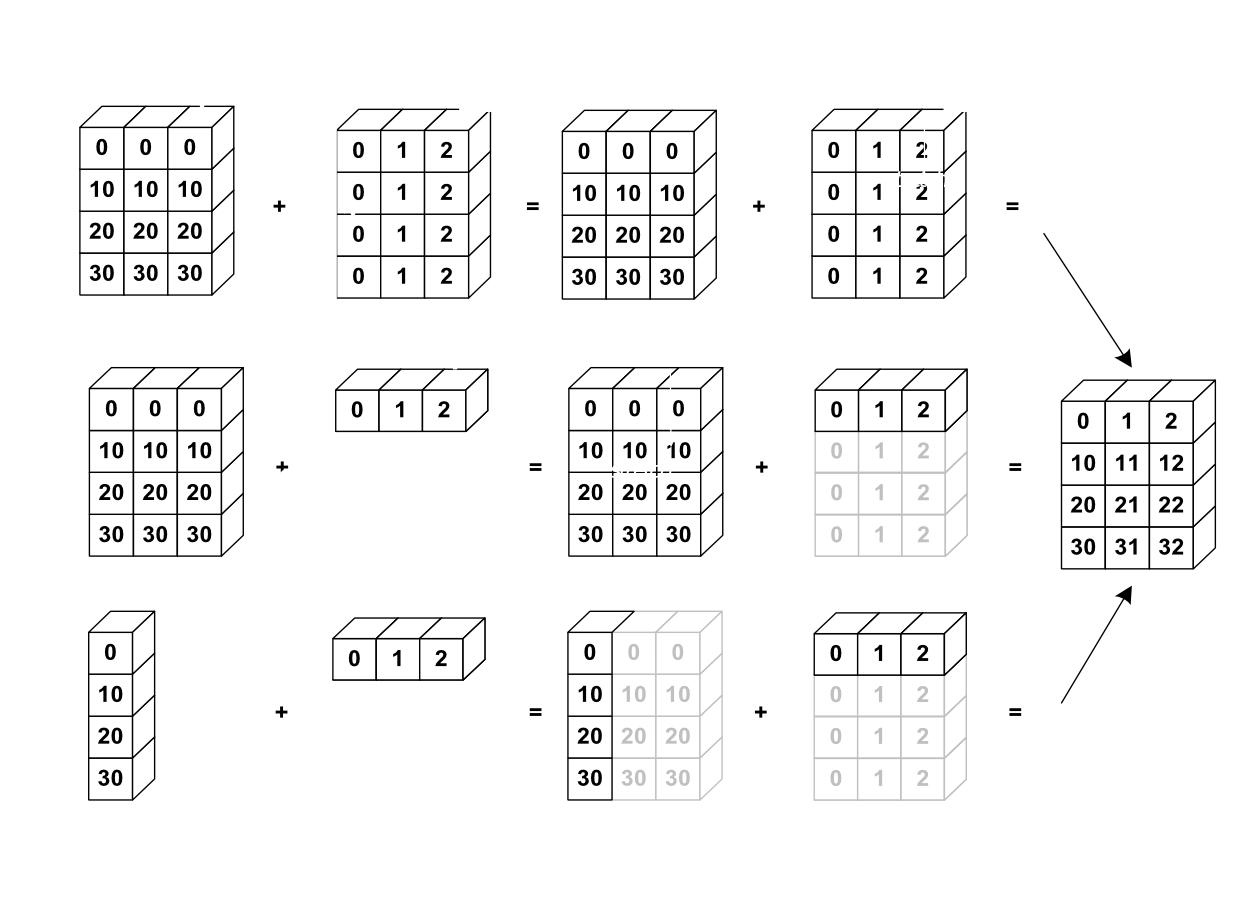
Für alle Methoden genügt es die Vektoren und Matrizen miteinander zu addieren. Bei der zweiten Methode muss allerdings sichergestellt sein, dass die Anzahl der Spalten des Vektors und der Matrix übereinstimmen.
Achtung
Die spaltenweise oder zeilenweise Addition funktioniert nur, wenn die Anzahl der Zeilen oder Spalten der Matrix und des Vektors identisch sind.
Bei der dritten Variante erstellt Python automatisch eine Matrix, die so viele Zeilen hat, wie der Zeilenvektor, und so viele Spalten wie der Spaltenvektor.
matrix = np.array([[0, 0, 0],[10, 10, 10],[20, 20, 20],[30, 30, 30]])
zeilenvektor = np.array([[0, 1, 2]])
spaltenvektor = np.transpose(np.array([[0, 10, 20, 30]]))
print(matrix + zeilenvektor)
print(spaltenvektor + zeilenvektor)
Die Addition funktioniert zuverlässig, wenn klar ist, dass es sich um einen Zeilenvektor (Form (1, n)) und einen Spaltenvektor (Form (m, 1)) handelt. Wird dagegen ein eindimensionales Array (Form (n,)) verwendet, kann die Addition mit einer Matrix (z. B. Form (m, n)) zwar funktionieren, aber die Kombination zweier eindimensionaler Arrays ist nicht ohne Weiteres möglich und führt zu einem Fehler.
matrix = np.array([[0, 0, 0],[10, 10, 10],[20, 20, 20],[30, 30, 30]])
zeilenvektor = np.array([0, 1, 2])
spaltenvektor = np.transpose(np.array([0, 10, 20, 30]))
# funktioniert
print(matrix + zeilenvektor)
# funktioniert nicht
print(zeilenvektor + spaltenvektor) # Fehler
Ganz analog zu Addition funktioniert auch die zeilenweise bzw. spaltenweise Multiplikation. Dazu betrachten wir das folgenden Beispiel. Angenommen, wir haben eine Matrix der historischen Renditen von vier Aktien über drei Jahre:
Nun möchten wir für jedes Jahr einen unterschiedlichen Steuerfaktor anwenden. Die Steuerfaktoren sind:
Die Matrix der Renditen nach Anwendung des jeweiligen Steuerfaktors für jedes Jahr ergibt sich durch die Multiplikation der \(k\)-ten Zeile der Matrix \(R\) mit dem \(k\)-ten Eintrag des Vektors Steuerfaktoren für \(k=1,2,3\).
Aufgabe 2.1
Berechnen Sie mit Hilfe der zeilenweise Multiplikation die tatsächlichten Renditen nach der Steuer und speichern Sie das Ergebnis in der Matrix \(\texttt{R_steuer}\).
# Renditenmatrix (3 Jahre x 4 Aktien)
R = np.array([
[0.05, 0.02, -0.01, 0.03],
[0.07, 0.04, 0.00, 0.05],
[-0.03, 0.01, 0.02, 0.01]
])
# Steuerfaktoren für jedes Jahr
steuerfaktoren = np.array([[0.9], [0.88], [0.92]])
# Ihr Code
Hinweis
Achten Sie auf die richtigen Dimensionen.
Lösung
# Anwendung der Steuerfaktoren auf die entsprechenden Zeilen der Matrix
R_steuer = R * steuerfaktoren
print("Matrix der Renditen nach Anwendung der Steuerfaktoren:")
print(R_steuer)
Aufgabe 2.2
Nutzen Sie Ihr neu hinzugewonnenes Wissen, um effizient (ohne Schleife) die Summe der Quadrate der ersten 100 natürlichen Zahlen zu berechnen.
# Ihr Code
Hinweis
Die Funktion \(\texttt{np.sum}\) könnte hilfreich sein.
Lösung
n = 100
# Erstellen eines Arrays mit Zahlen von 1 bis n
zahlen = np.arange(1, n + 1)
# Berechnung der Summe der Quadrate
summe_quadrate = np.sum(zahlen**2)
# Erstellen eines Arrays mit Zahlen von 1 bis n
zahlen = np.arange(1, n + 1)
# Berechnung der Summe der Quadrate
summe_quadrate = np.sum(zahlen**2)
print(f"Die Quadratsumme der ersten {n} natürlichen Zahlen ist: {summe_quadrate}")
Erinnern Sie sich an das Beispiel aus dem Kapitel Fehleranzeige zurück, bei dem Produkte gemäß Gewichte im Bezug auf sechs verschiedene Merkmale bewertet werden sollten.
Aufgabe 2.3
Vektorisieren Sie die Funktion \(\texttt{score_berechnung(P, w)}\). Lassen Sie den Code zunächst ohne Bearbeitung durchlaufen, um sich zu vergewissern, welche Werte herauskommen sollten.
def score_berechnung(P, w):
"""
Berechnet die gewichteten Scores für Produkte.
EINGABE:
- P: numpy Array mit Produktinformationen (erste Spalte sind Nummern, restliche Spalten sind Merkmale)
- w: numpy Array mit Gewichtungen für jedes Merkmal
AUSGABE:
- scores: numpy Array mit Produktnummern und gewichteten Scores
"""
ids = P[:, 0] # Produktnummern
values = P[:, 1:] # Merkmale
## TODO
for i in range(values.shape[1]):
values[:, i] = values[:, i] / np.max(values[:, i])
## TODO
scores = np.zeros(len(ids))
for i in range(len(ids)):
for j in range(len(w)):
scores[i] = scores[i] + values[i, j] * w[j]
product_scores = np.column_stack((ids, scores))
return product_scores
# Beispiel-Daten um Code zu testen
products = np.array(
[
[1, 90, 85, 30, 80, 500, 1200],
[2, 80, 90, 20, 85, 200, 1500],
[3, 85, 80, 25, 90, 1000, 800],
[4, 70, 75, 40, 75, 250, 500],
[5, 95, 90, 15, 97, 400, 1300],
[6, 97, 80, 35, 80, 300, 1200],
[7, 80, 85, 30, 85, 500, 1400],
[8, 75, 78, 28, 85, 350, 1100],
[9, 88, 82, 32, 88, 600, 1600],
[10, 76, 82, 30, 80, 350, 1100],
],
dtype=float,
)
weights = np.array([0.4, 0.25, -0.15, 0.15, 0.05, 0.05])
# Berechnung der Scores
product_scores = score_berechnung(products, weights)
for product, score in product_scores:
print(f"Produkt {int(product)}: {score:.2f}")
Hinweis
Die Funktionen \(\texttt{np.max}\) und \(\texttt{np.dot}\) könnten hilfreich sein.
Lösung
def score_berechnung(P, w):
"""
Berechnet die gewichteten Scores für Produkte.
EINGABE:
- P: numpy Array mit Produktinformationen (erste Spalte sind Nummern, restliche Spalten sind Merkmale)
- w: numpy Array mit Gewichtungen für jedes Merkmal
AUSGABE:
- scores: numpy Array mit Produktnummern und gewichteten Scores
"""
ids = P[:, 0] # Produktnummern
values = P[:, 1:] # Merkmale
# Normalisierung der Merkmale (nur einmal pro Merkmal)
values = values / np.max(values, axis=0)
# Berechnung der Scores mit vektorisierten Operationen
scores = np.dot(values, w) # Gewichtete Merkmale aufsummieren
# Kombiniere Produktnummern mit Scores
product_scores = np.column_stack((ids, scores))
return product_scores
Übersicht
Zum Abschluss dieses Kapitels geben wir Ihnen eine Übersicht von vielen verschiedenen Methoden, um seinen Code effizienter zu gestalten. Die Tabelle ist lediglich für Sie in der Zukunft als Nachschlagewerk gedacht.
Mechanismus |
Beschreibung |
Beispiel |
|---|---|---|
Broadcasting |
Ermöglicht es, Operationen auf Arrays unterschiedlicher Größe anzuwenden, indem kleinere Arrays automatisch auf die Form des größeren Arrays angepasst werden. |
\(\texttt{np.add(arr1, arr2)}\) wenn \(\texttt{arr1}\) (3,1) und \(\texttt{arr2}\) (1,3) sind. |
Array-Operationen |
Mathematische Operationen wie Addition, Subtraktion, Multiplikation und Division werden auf ganze Arrays angewendet, ohne explizite Schleifen. |
\(\texttt{np.array([1, 2, 3]) + 10}\) ergibt \(\texttt{array([11, 12, 13])}\). |
\(\texttt{np.vectorize()}\) |
Mit \(\texttt{np.vectorize()}\) können benutzerdefinierte Funktionen auf ganze Arrays angewendet werden, ohne explizite Schleifen. |
\(\texttt{np.vectorize(lambda x: x ** 2)(arr)}\) berechnet das Quadrat jedes Elements im Array \(\texttt{arr}\). |
Trigonometrische Funktionen |
NumPy bietet eine Vielzahl von trigonometrischen Funktionen wie \(\texttt{np.sin()}\), \(\texttt{np.cos()}\), \(\texttt{np.tan()}\) usw. für jedes Element im Array. |
\(\texttt{np.sin(arr)}\) berechnet den Sinus jedes Elements im Array \(\texttt{arr}\). |
\(\texttt{np.matmul()}\) |
Führt eine Matrixmultiplikation durch. Ähnlich wie \(\texttt{np.dot()}\), aber speziell für 2D-Arrays optimiert. |
\(\texttt{np.matmul(A, B)}\) berechnet das Matrixprodukt der Matrizen \(A\) und \(B\). |
\(\texttt{np.multiply()}\) |
Berechnet die elementweise Multiplikation zwischen Arrays. |
\(\texttt{np.multiply(arr1, arr2)}\) multipliziert die Arrays \(\texttt{arr1}\) und \(\texttt{arr2}\) elementweise. |
Ufuncs (Universal Functions) |
Ufuncs sind vektorisierte Funktionen, die auf ganze Arrays angewendet werden und elementweise Operationen effizient ausführen. |
|